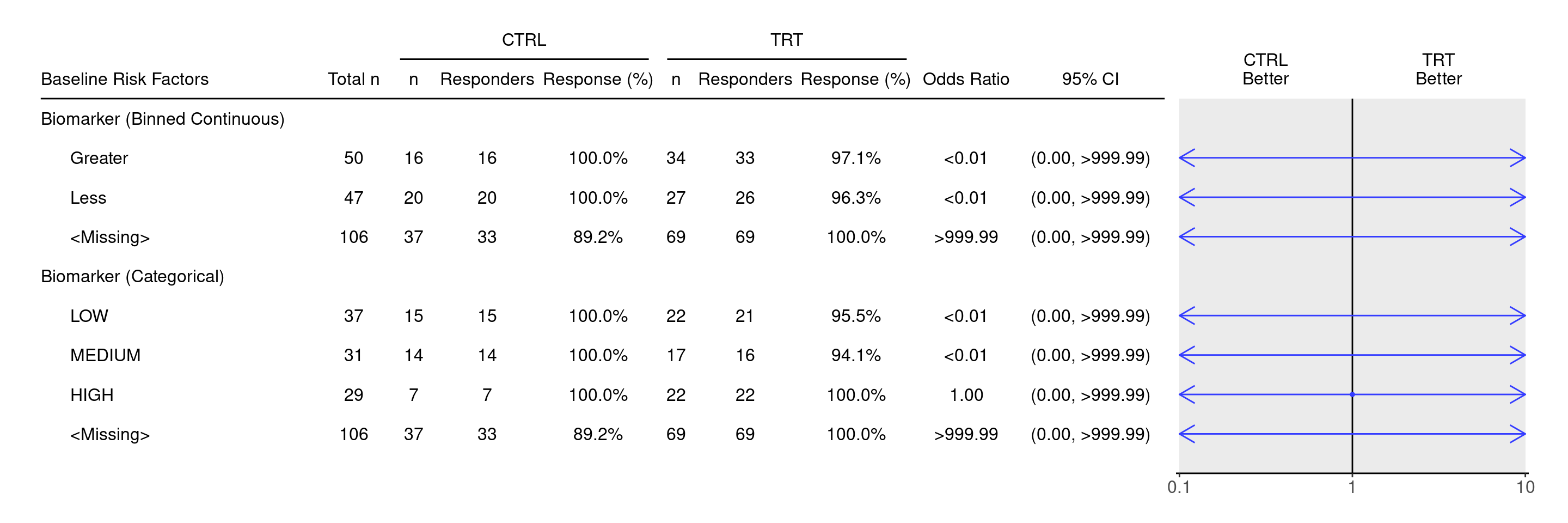
These templates are helpful when we are interested in the odds ratios between two groups, usually two treatment arms. We would like to assess how the odds ratio changes when we look at different subgroups, often defined by categorical biomarker variables, e.g.
We will use the cadrs data set from the random.cdisc.data package to create the response forest graph. We start by filtering the adrs data set for the Best Confirmed Overall Response by Investigator and patients with measurable disease at baseline (BMEASIFL == "Y"). We create a new variable for response information (we define response patients to include CR and PR patients), and binarize the ARM variable. We also fix a data artifact by setting the categorical biomarker variable BMRKR2 to an explicit <Missing> level for the non-biomarker evaluable population.
We also relabel the biomarker evaluable population flag variable BEP01FL and the categorical biomarker variable BMRKR2 to update the display label of these variables in the graph.
We define a binned factor variable BMRKR1_cut from the continuous biomarker variable BMRKR1 to illustrate. Note that the remaining code would work the same for an originally categorical biomarker.
---title: RFG1Asubtitle: Response Forest Graph Only by Categorical or Binned Continuous Biomarkercategories: [RFG]---------------------------------------------------------------------------::: panel-tabset{{< include setup.qmd >}}## PlotWe define a binned factor variable `BMRKR1_cut` from the continuous biomarker variable `BMRKR1` to illustrate.Note that the remaining code would work the same for an originally categorical biomarker.```{r, fig.width = 15}BMRKR1_cutpoint <-5adrs2 <- adrs %>%mutate(BMRKR1 =ifelse(BEP01FL =="N", NA, BMRKR1),BMRKR1_cut =explicit_na(factor(ifelse(BMRKR1 > BMRKR1_cutpoint, "Greater", "Less") )) ) %>%var_relabel(BMRKR1_cut ="Biomarker (Binned Continuous)")df <-extract_rsp_subgroups(variables =list(rsp ="is_rsp",arm ="ARM_BIN",subgroups =c("BMRKR1_cut", "BMRKR2") ),data = adrs2,conf_level =0.95)result <-basic_table() %>%tabulate_rsp_subgroups(df, vars =c("n_tot", "n", "n_rsp", "prop", "or", "ci"))```We can remove the first line showing the `All Patients` category from the `result` table as follows.```{r}result <- result[-1, , keep_topleft =TRUE]```We can then produce the forest plot again using `g_forest()` on this trimmed `result` table.```{r, fig.width = 15}g_forest(result)```{{< include ../../misc/session_info.qmd >}}:::