RNAG9
RNAseq Kaplan-Meier Graph
This page can be used as a template of how to produce Kaplan-Meier graphs for RNA-seq gene expression analysis using available tern and hermes functions, and to create an interactive Kaplan-Meier graph for RNA-seq gene expression analysis using teal.modules.hermes.
The code below needs both RNA-seq data (in HermesData format) and time-to-event data (in ADTTE format) as input.
We first prepare the time-to-event data. We define an event indicator variable, transform the time to months and filter down to the overall survival subset.
Then we prepare the RNA-seq data. See RNAG1 for basic details on how to import, filter and normalize HermesData. We use col_data_with_genes() to extract the sample variables (colData) from the object, together with a single specified gene or a specified gene signature. See ?hermes::gene_spec for details on how to do this. Then we use inner_join_cdisc() to join this genetic data with the ADTTE data from above. See the help page for more details, in particular how the join keys can be customized if needed - here we just join based on USUBJID by default.
We can then cut the resulting gene column (we figure out the column name and save it in arm_name below) in the joined_data into quantile bins (in this example we want three equally sized groups).
It is now simple to create the Kaplan-Meier graph by providing the data set created above with the variable specification. Note that we specify the above created gene_factor as arm variable here.
Code
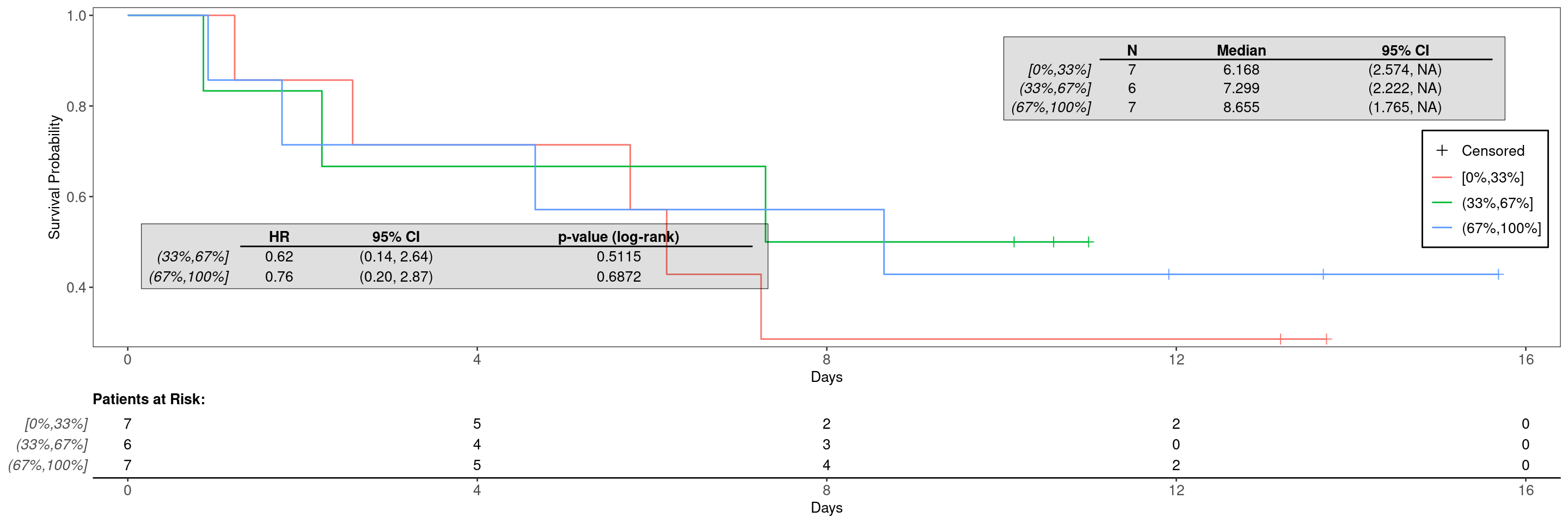
See KG1 to KG5 for additional customization options for the Kaplan-Meier graphs or the help page ?g_km().
We start by importing a MultiAssayExperiment and sample ADTTE data; here we use the example multi_assay_experiment available in hermes and example ADTTE data from random.cdisc.data. We can then use the provided teal module tm_g_km to include the corresponding interactive Kaplan-Meier analysis in our teal app. Note that by default the counts assay is excluded via the exclude_assays argument, but we can include it by just saying that we don’t want to exclude any assays. In case that we have different non-standard column names in our ADTTE data set we could also specify them via the adtte_vars argument, see the documentation ?tm_g_km for more details.
Code
library(teal.modules.hermes)
data <- teal_data()
data <- within(data, {
library(random.cdisc.data)
library(dplyr)
library(hermes)
MAE <- multi_assay_experiment
ADTTE <- random.cdisc.data::cadtte %>%
mutate(is_event = .data$CNSR == 0)
})
datanames(data) <- c("MAE", "ADTTE")
join_keys(data)["ADTTE", "ADTTE"] <- c("STUDYID", "USUBJID", "PARAMCD")
app <- init(
data = data,
modules = modules(
tm_g_km(
label = "Kaplan-Meier Graph",
adtte_name = "ADTTE",
mae_name = "MAE",
exclude_assays = character()
)
)
)
shinyApp(app$ui, app$server)Warning: 'experiments' dropped; see 'drops()'
R version 4.4.1 (2024-06-14)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] random.cdisc.data_0.3.15.9009 teal.modules.hermes_0.1.6.9020
[3] teal_0.15.2.9061 teal.slice_0.5.1.9011
[5] teal.data_0.6.0.9010 teal.code_0.5.0.9009
[7] shiny_1.9.1 hermes_1.7.2.9002
[9] SummarizedExperiment_1.34.0 Biobase_2.64.0
[11] GenomicRanges_1.56.1 GenomeInfoDb_1.40.1
[13] IRanges_2.38.1 S4Vectors_0.42.1
[15] BiocGenerics_0.50.0 MatrixGenerics_1.16.0
[17] matrixStats_1.4.1 ggfortify_0.4.17
[19] ggplot2_3.5.1 dplyr_1.1.4
[21] tern_0.9.5.9022 rtables_0.6.9.9014
[23] magrittr_2.0.3 formatters_0.5.9.9001
loaded via a namespace (and not attached):
[1] RColorBrewer_1.1-3 jsonlite_1.8.8
[3] shape_1.4.6.1 MultiAssayExperiment_1.30.3
[5] farver_2.1.2 rmarkdown_2.28
[7] GlobalOptions_0.1.2 zlibbioc_1.50.0
[9] vctrs_0.6.5 memoise_2.0.1
[11] webshot_0.5.5 BiocBaseUtils_1.7.3
[13] htmltools_0.5.8.1 S4Arrays_1.4.1
[15] forcats_1.0.0 progress_1.2.3
[17] curl_5.2.2 broom_1.0.6
[19] SparseArray_1.4.8 sass_0.4.9
[21] parallelly_1.38.0 bslib_0.8.0
[23] fontawesome_0.5.2 htmlwidgets_1.6.4
[25] httr2_1.0.3 cachem_1.1.0
[27] teal.widgets_0.4.2.9020 mime_0.12
[29] lifecycle_1.0.4 iterators_1.0.14
[31] pkgconfig_2.0.3 webshot2_0.1.1
[33] Matrix_1.7-0 R6_2.5.1
[35] fastmap_1.2.0 future_1.34.0
[37] GenomeInfoDbData_1.2.12 rbibutils_2.2.16
[39] clue_0.3-65 digest_0.6.37
[41] colorspace_2.1-1 shinycssloaders_1.1.0
[43] ps_1.8.0 AnnotationDbi_1.66.0
[45] RSQLite_2.3.7 filelock_1.0.3
[47] labeling_0.4.3 fansi_1.0.6
[49] httr_1.4.7 abind_1.4-8
[51] compiler_4.4.1 bit64_4.0.5
[53] withr_3.0.1 doParallel_1.0.17
[55] backports_1.5.0 DBI_1.2.3
[57] logger_0.3.0 biomaRt_2.60.1
[59] rappdirs_0.3.3 DelayedArray_0.30.1
[61] rjson_0.2.22 chromote_0.3.1
[63] tools_4.4.1 httpuv_1.6.15
[65] glue_1.7.0 callr_3.7.6
[67] promises_1.3.0 grid_4.4.1
[69] checkmate_2.3.2 cluster_2.1.6
[71] generics_0.1.3 gtable_0.3.5
[73] websocket_1.4.2 tidyr_1.3.1
[75] hms_1.1.3 xml2_1.3.6
[77] utf8_1.2.4 XVector_0.44.0
[79] ggrepel_0.9.6 foreach_1.5.2
[81] pillar_1.9.0 stringr_1.5.1
[83] later_1.3.2 circlize_0.4.16
[85] splines_4.4.1 BiocFileCache_2.12.0
[87] lattice_0.22-6 survival_3.7-0
[89] bit_4.0.5 tidyselect_1.2.1
[91] ComplexHeatmap_2.20.0 Biostrings_2.72.1
[93] knitr_1.48 gridExtra_2.3
[95] teal.logger_0.2.0.9009 xfun_0.47
[97] stringi_1.8.4 UCSC.utils_1.0.0
[99] yaml_2.3.10 shinyWidgets_0.8.6
[101] evaluate_0.24.0 codetools_0.2-20
[103] tibble_3.2.1 cli_3.6.3
[105] xtable_1.8-4 Rdpack_2.6.1
[107] jquerylib_0.1.4 processx_3.8.4
[109] munsell_0.5.1 teal.reporter_0.3.1.9015
[111] Rcpp_1.0.13 globals_0.16.3
[113] dbplyr_2.5.0 png_0.1-8
[115] parallel_4.4.1 assertthat_0.2.1
[117] blob_1.2.4 prettyunits_1.2.0
[119] listenv_0.9.1 scales_1.3.0
[121] purrr_1.0.2 crayon_1.5.3
[123] GetoptLong_1.0.5 rlang_1.1.4
[125] formatR_1.14 cowplot_1.1.3
[127] KEGGREST_1.44.1 shinyjs_2.1.0