These templates are helpful when we are interested in modelling the effects of continuous biomarker variables on a time-to-event (survival) outcome, conditional on covariates and/or stratification variables included in Cox proportional hazards regression models. We would like to assess how the estimates effects change when we look at different subgroups.
In detail the differences to the other survival forest graphs (SFG1 to SFG5) are the following:
The extract_survival_subgroups() and tabulate_survival_subgroups() functions evaluate the treatment effects comparing two arms, across subgroups. On the other hand, the extract_survival_biomarkers() and tabulate_survival_biomarkers() functions used here in SFG6 evaluate the effects from continuous biomarkers in the Cox proportional hazards models, across subgroups.
The extract_survival_subgroups() and tabulate_survival_subgroups() functions only allow specification of a single treatment arm variable, while the extract_survival_biomarkers() and tabulate_survival_biomarkers() allow to look at multiple continuous biomarker variables at once.
In addition to the treatment arms, the use of extract_survival_subgroups() and tabulate_survival_subgroups() functions can be extended to other binary variables, as done in SFG3 and SFG4. For example, we could define the binarized ARM variable as AGE>=65 vs. AGE<65 and then look at the odds ratios across subgroups. For the extract_survival_biomarkers() and tabulate_survival_biomarkers() functions, we could use the original continuous biomarker variable AGE, and then look at the estimated effect across subgroups.
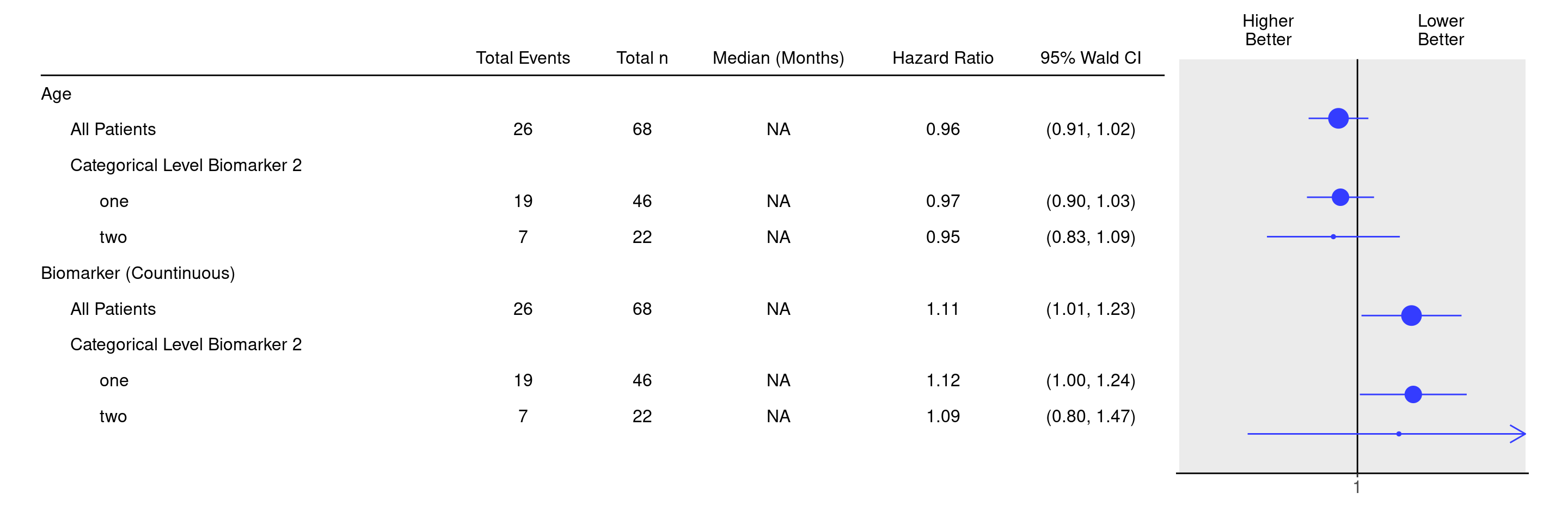
Similarly like in SFG3, we will use the cadtte data set from the random.cdisc.data package. Here we just filter for the overall survival outcome in a single arm in the biomarker evaluable population.
It is also possible to join and select subgroup categories manually using the groups_lists argument, as follows. Here we join the low and medium levels of BMRKR2 into a category one and compare with the high level labeled as category two.
---title: SFG6Bsubtitle: Survival Forest Graph for Multiple Continuous Biomarkers by Manual Subgroup Categoriescategories: [SFG]---------------------------------------------------------------------------::: panel-tabset{{< include setup.qmd >}}## PlotIt is also possible to join and select subgroup categories manually using the `groups_lists` argument, as follows.Here we join the low and medium levels of `BMRKR2` into a category `one` and compare with the high level labeled as category `two`.```{r, fig.width = 15}df <- extract_survival_biomarkers( variables = list( tte = "AVAL", is_event = "is_event", biomarkers = c("BMRKR1", "AGE"), covariates = "SEX", subgroups = "BMRKR2" ), data = adtte_f, groups_list = list( BMRKR2 = list( one = c("LOW", "MEDIUM"), two = "HIGH" ) ))result <- tabulate_survival_biomarkers( df = df, vars = c("n_tot_events", "n_tot", "median", "hr", "ci"), time_unit = adtte_f$AVALU[1])g_forest(result, xlim = c(0.7, 1.4))```{{< include ../../misc/session_info.qmd >}}:::