We will use the cadtte data set from the random.cdisc.data package to create the survival forest graph. We start by filtering the adtte data set for the overall survival observations, converting time of overall survival to months, creating a new variable for event information, binarizing the ARM variable and creating a binned age variable by using the function cut_quantile_bins(). Note that we do not include the boundaries 0 and 1 in the corresponding cutoffs vector AGE_probs, but only the true cutoff probabilities to use (here 0.5, i.e. the median). We restrict the analysis of the biomarker variables BMRKR1 and BMRKR2 to the BEP by setting them as missing for the non-BEP.
We also relabel the biomarker evaluable population flag variable BEP01FL and the categorical biomarker variable BMRKR2 to update the display label of these variables in the graph.
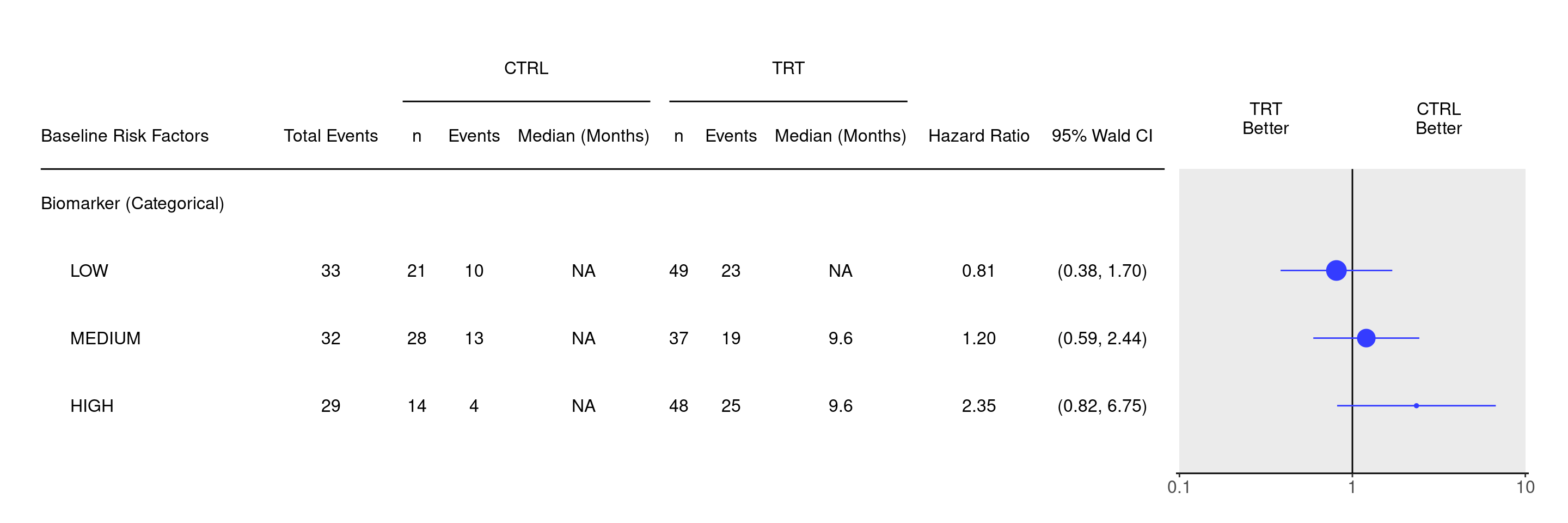
We can now remove the first line with All Patients and the last line with the <Missing> category from the result table to display the survival forest plot only by the categorical biomarker BMRKR2.
Code
result <- result[c(-1, -6), , keep_topleft =TRUE]
We can then again produce the forest plot using g_forest().
---title: SFG1Asubtitle: Survival Forest Graph Only by Categorical Biomarkercategories: [SFG]---------------------------------------------------------------------------::: panel-tabset{{< include setup.qmd >}}## PlotThis works analogously to [SFG1](sfg01.qmd), we just only include `BMRKR2` in the `subgroups` list element.```{r}tbl <-extract_survival_subgroups(variables =list(tte ="AVAL",is_event ="is_event",arm ="ARM_BIN",subgroups ="BMRKR2" ),data = adtte)result <-basic_table() %>%tabulate_survival_subgroups(df = tbl,vars =c("n_tot_events", "n", "n_events", "median", "hr", "ci"),time_unit = adtte$AVALU[1] )```We can now remove the first line with `All Patients` and the last line with the `<Missing>` category from the `result` table to display the survival forest plot only by the categorical biomarker `BMRKR2`.```{r}result <- result[c(-1, -6), , keep_topleft =TRUE]```We can then again produce the forest plot using `g_forest()`.```{r, fig.width = 15}g_forest(result)```{{< include ../../misc/session_info.qmd >}}:::