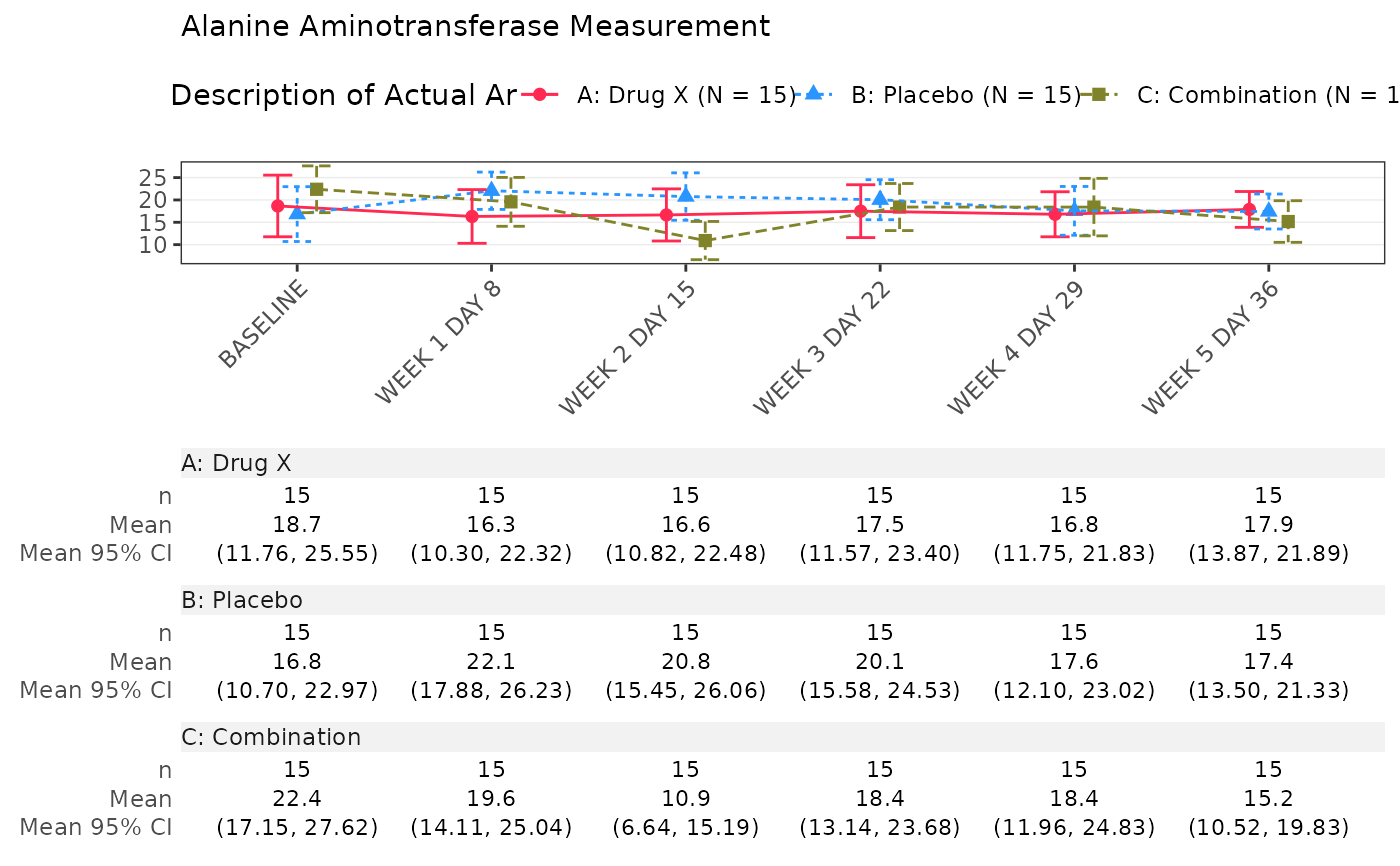
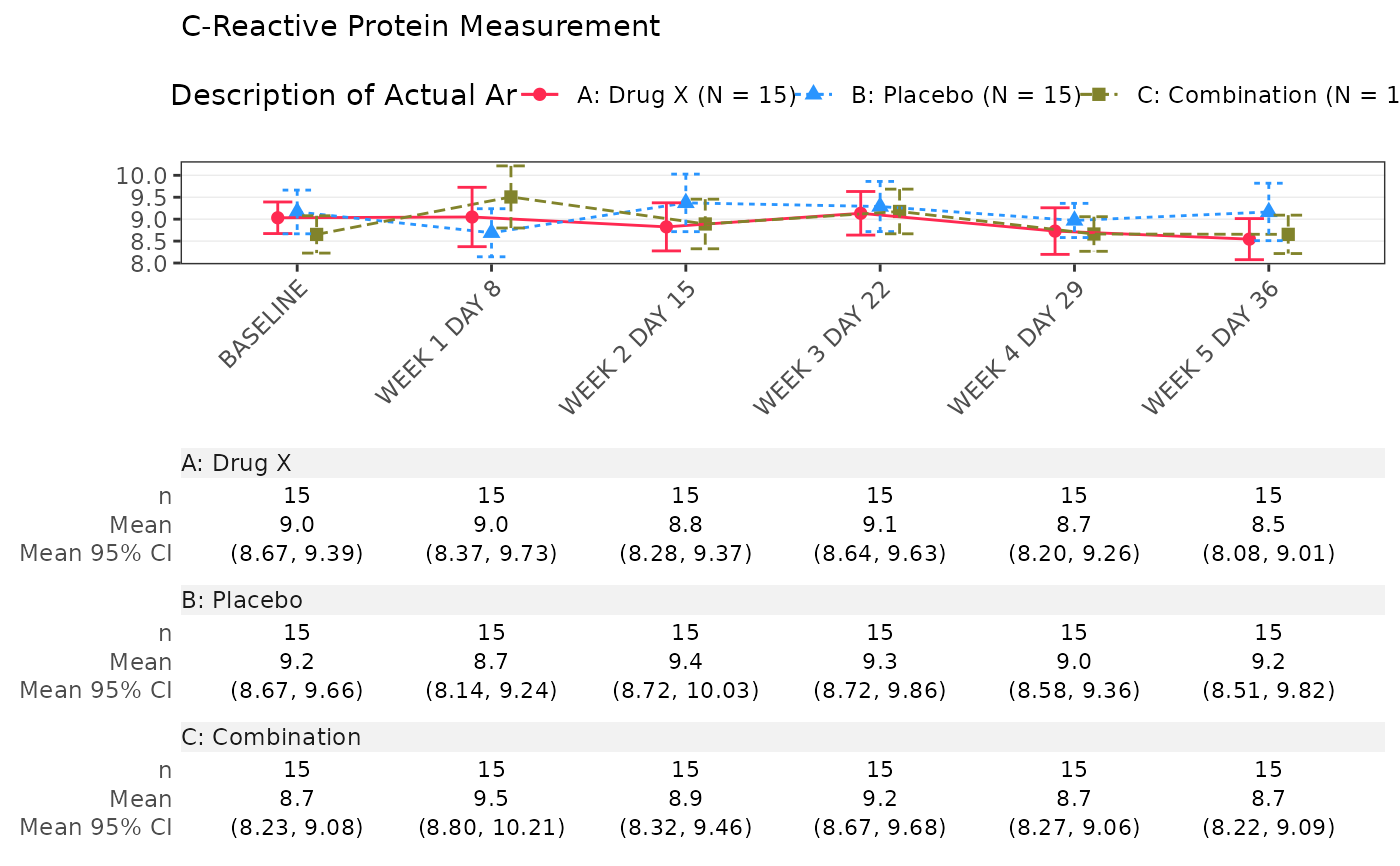
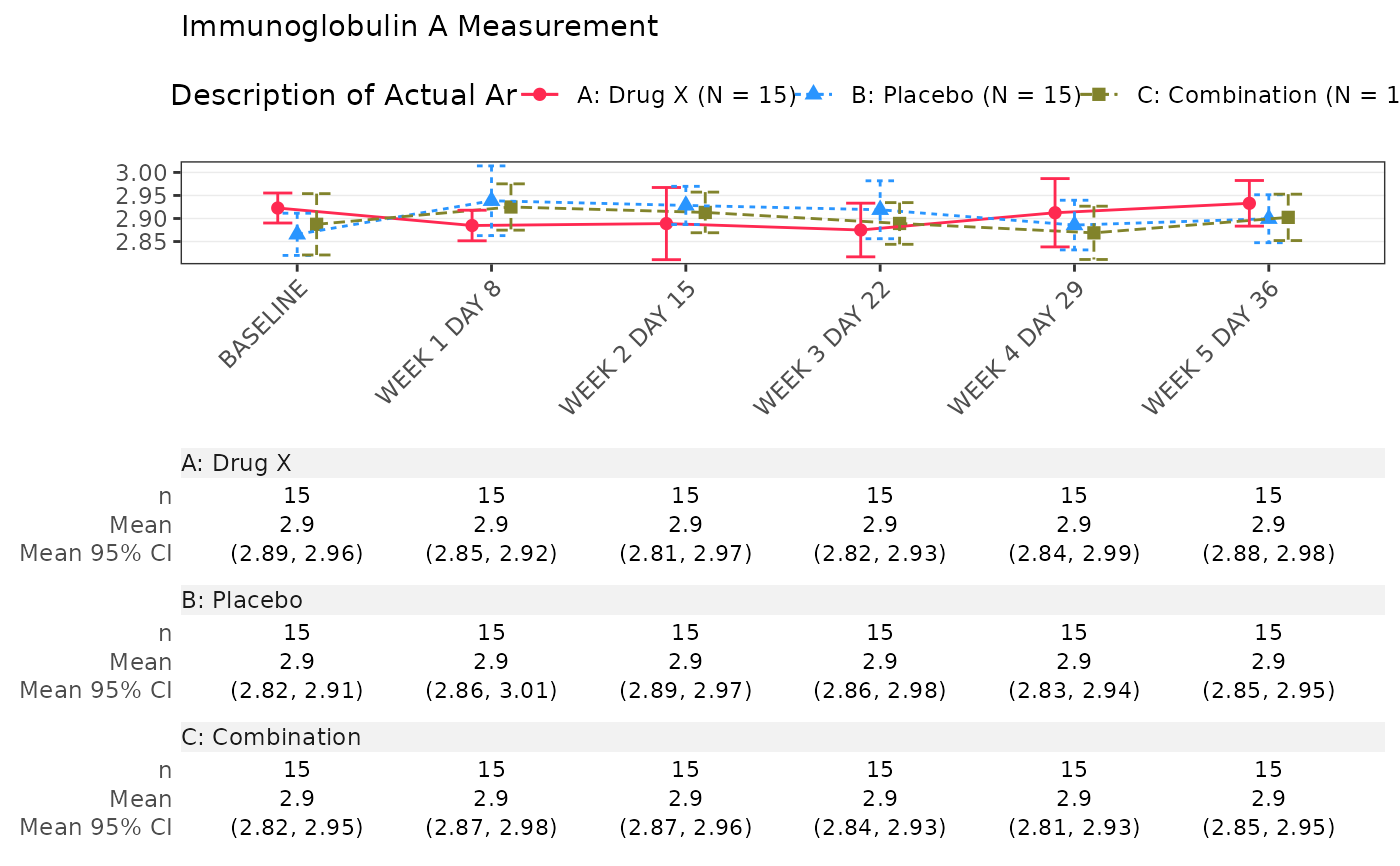
Run the TLG-generating pipeline
Usage
run(
object,
adam_db,
auto_pre = TRUE,
verbose = FALSE,
unwrap = FALSE,
...,
user_args = list(...)
)
# S4 method for class 'chevron_tlg'
run(
object,
adam_db,
auto_pre = TRUE,
verbose = get_arg("chevron.run.verbose", "R_CHEVRON_RUN_VERBOSE", FALSE),
unwrap = get_arg("chevron.run.unwrap", "R_CHEVRON_RUN_UNWRAP", verbose),
...,
user_args = list(...)
)Arguments
- object
(
chevron_tlg) input.- adam_db
(
listofdata.frames) object containing theADaMdatasets- auto_pre
(
flag) whether to perform the default pre processing step.- verbose
(
flag) whether to print argument information.- unwrap
(
flag) whether to print the preprocessing postprocessing and main function together with the associated layout function.- ...
extra arguments to pass to the pre-processing, main and post-processing functions.
- user_args
(
list) arguments from....
Value
an rtables (for chevron_t), rlistings (for chevron_l), grob (for chevron_g) or ElementaryTable
(null report) depending on the class of chevron_tlg object passed as object argument.
Details
The functions stored in the preprocess, main and postprocess slots of the chevron_tlg objects are called
respectively, preprocessing, main and postprocessing functions.
When executing the run method on a chevron_tlg object, if auto_pre is TRUE, the adam_bd list is first
passed to the preprocessing function. The resulting list is then passed to the main function which produces a
table, graph or listings or a list of these objects. This output is then passed to the postprocessing function
which performed the final modifications before returning the output. Additional arguments specified in ... or
user_args are passed to each of the three functions.